

ピックアップレポート
2004年05月11日
マーケティング研究と統計的手法
はじめに
マーケティング研究は、売手と買手の取引や相互作用プロセスとして表出される複雑な現象を対象とする。しかも、これはミクロおよびマクロの両面から捉えることができる。例えば、あるTVコマーシャルが消費者の購買意欲に及ぼす影響は、ミクロ的なマーケティング現象として、他方、広告一般が企業間競争や物価に及ぼす影響は、マクロ的なそれとして、それぞれ認識可能である。マーケティング研究の目的は、このようなマーケティング現象を記述・説明し、さらには予測したり、あるいは、企業等の意思決定主体の目標に沿うようにそれを統制したりすることにある。したがって、こうした作業の究極的目的は、マーケティング理論の構築と、マーケティング管理にとって有用な知識の獲得にある。以下では、そのようなマーケティング研究において有益な統計的手法とそのためのデータについて概観すると共に、その役割や限界について整理する。
第1節 マーケティング研究における統計的手法の役割
本節では、上述のようなマーケティング研究の目的を達成する上で、統計的な手法が如何なる役割を果たしているかについてまず簡潔に述べることにしよう。
第1に、マーケティング現象の記述とは、その克明な描写を意味する。それは研究対象となった現象が、どのようなものであるかを客観的事実として把握することである。つまり、記述の目的は、その現象に対する総合的理解を深めることであり、その副産物として、現象の発生メカニズムや因果構造に関する仮説が得られることもある。記述は文書(言語モデル)の形で行うことも可能であるが、その現象の特性を変数で捉え、評点、度数、比率、平均、分散等の数量として示すこともできる。
第2に、説明とは、研究対象となったマーケティング現象の構造や発生メカニズムを、原因を特定した上で客観的に明らかにすることである。そのためには、対象となる現象を被説明変数(基準変数、または、従属変数)として捉え、その現象の原因と仮定される説明変数(予測変数、または、独立変数)との関係を統計的に明示する必要がある。これらの変数間の関係を示した数式(例えば、回帰式)は説明モデルと呼ばれる。以上のように記述と説明は、マーケティング現象が「どのようになっているか。また、それはなぜか。」という問いに答えるものである。
第3に、予測は、言うまでもなく、対象とするマーケティング現象の予測である。そのためには、説明段階で得られた統計モデル、時系列データを用いた予測のためのモデル、さらには、シミュレーション・モデルなどを利用する。例えば、既に得られている説明モデル(ここでは、回帰式)を用いる場合、独立変数に予測すべき時点のデータを代入することで、従属変数の値が予測できる。ただし、予測は単にマーケティング現象の未来変化を知るためだけでなく、導かれた説明モデルの時間的ないしは空間的妥当性をテストすることによって、より説明力の高いモデルを得るためにも行われる。ここで、説明を主たる目的とする場合には、できるだけ少数の独立変数で現象を説明することが望ましいのに対し、単に予測力の向上をめざす場合は、個々の独立変数の説明力よりもそれら全体としての予測精度の方が重視されるため、必ずしもそれらが少数である必要はない。
最後に、統制はマーケティング現象が「どうあるべきか。」という問いに答える。つまり、統制を目的とする研究は、マーケティング現象を最も有効に統制し得るような戦略を意思決定者(通常は、企業のマーケティング担当者)に与えるためのものである。記述、説明、予測が、マーケティングの基礎理論の構築を目指すとすれば、統制はマーケティング管理上の知識を追求するきわめて応用的なものと言える。ただし、統制は記述・説明・予測と独立に存在するのではなく、むしろ、そうした作業から得られた客観的知識に基づいてなされるべきである。
第2節 各種データの性質と入手法
統計解析に用いることのできるデータは様々である。しかし、統計解析にそのまま用いることができるのは、そうしたデータの一部にしか過ぎない。しかし、そのままでは統計解析の対象とならない質的データでも、量的データに変換して統計解析に用いたり、それがカテゴリカル・データであれば、そのための解析手法を用いたりすることもできる。さらに、内容分析などの質的データの分析プロセスには、キーワードの集計という形でデータの数量的取扱が含まれている。本節では、各種データの特性と入手方法、それらに対する統計的手法の適用の問題について概観する。
【1.一次データ】
調査者の何らかの意図に基づいて新たに収集されるデータを一次データと言う。一次データを入手するための方法としては、以下のような方法がある。ただし、収集されたデータが、すべてそのままの形で統計解析の対象となるとは限らない。質的なデータについては、何らかの方法で数量的なデータに変換したり、量的データであっても加工したりしてから統計解析手法を適用する場合もある。
- 実査(サーベイ)
一般にアンケート調査と呼ばれる。5点尺度などで測定された各質問項目は、それぞれ変数を意味する。多くの回答者から得られた諸変数についてのデータは数量データとして扱われ、統計解析の対象となる。ただし、性別や職業などカテゴリカルなデータは質的データであるため、分散分析などカテゴリカル・データを扱うための分析技法を採用したり、ダミー変数に変換して回帰分析に掛けたりするなどの工夫が必要である。また、自由回答による記述は、そのままでは量的分析の対象とはならないため、質的データのところで後述するような分析方法を取る必要がある。
- 深層面接およびグループ・インタビュー調査
新製品開発のヒントや隠れた消費者ニーズを把握するために、しばしばこの種の調査方法が用いられる。しかし、これらの方法で集められた情報は質的データであるため、統計解析の対象とはなりにくい。 実査(サーベイ)における自由回答も含め、定性的調査によって得られたデータをいかに客観的な情報に変換するかについては後述する。
- 観察
調査対象(一般には消費者)の行動を捉えデータ化する方法。その例としては、新規店舗の出店可能性を探るための交通量調査、小売店内の顧客の通行を把握し売場作りための知見を得る顧客動線調査、広告物や店内陳列物に対する消費者の視線の動きを記録するアイカメラによる方法などが挙げられる。小売店に蓄積されるPOSデータも一種の観察データである。これらはいずれも客観的に記録されたデータではあるが、消費者別、店舗別、あるいは製品別といった具合に集計し直し、それらの標本を一定数確保しなければ、統計的分析の適用は困難である。
- 実験
実験室的な環境の中でデータを収集する方法と、実際の市場においてデータを収集するテスト・マーケティングや擬似実験的な方法とが存在する。まず、実験室的な方法の例としては、異なるパターンの広告を提示してその反応を比較する方法が考えられる。また、擬似実験的方法としては、異なる地域や店舗において異なるマーケティング対応(異なる製品の販売、異なる価格や広告の提示等)を行って、その結果を見る方法がある。この種の方法では、実験的刺激のあるなしが、0ないしは1のダミー変数として把握され、それが結果(売上や消費者の好意的反応度など)に如何なる影響をもつかを統計的に明らかにしようという発想が基本にある。
【2.二次データ】
これに対し、他者によって収集されたデータを事後的に借用して統計解析に用いる場合があるが、これを二次データと呼ぶ。一般に調査予算には限界があり調査の重複を回避するためにも、まず社内に蓄積されたデータや外部の研究機関・組織・マスコミ等によって公表されたデータを有効に活用しようと考えるのが自然である。具体的には、国勢調査や商業統計等の公的機関による調査データ、マスコミ・広告代理店・金融機関・保険会社等によるレポート、新聞ないしは雑誌記事、各種統計データベース、インターネットのホームページ等からの情報が利用可能である。
【3.量的データ】
統計解析に用いられるデータは、量的データがその中心となる。量的データとは、一般に加算が可能なデータのことで、後述する間隔尺度と比尺度がこれに含まれる。他方、質的データには、まず、名義尺度および序数尺度で測定されたものと、次に、言葉や文章(テキスト)として記録されたものが含まれる。名義尺度と序数尺度による変数は、量的変数に適応されるものとは異なるカテゴリカル・データのための解析手法が開発されてきた。また、類似性や選好など量的に把握することが困難な対象を、データ入手の段階から序数的な量として回答させ解析するための手法(例.多次元尺度構成法、コンジョイント分析)も存在する。一般にデータはその測定の水準によって次の4つのタイプに大別され、特性の違いによって適応可能な解析技法も異なることが多い。
-
名義尺度
学籍番号や銀行の口座番号のように個々の対象を単に識別するための数値をもつものを指す。許容される統計量としては、事例数、最頻値などがある。性別や職業のようにそのままでは数値として取り扱えない質的データは、カテゴリカル・データと呼ばれ、性別を男なら0、女なら1という具合にダミー変数に変換することによって数量データとしての利用可能性が開ける。数学的性質としては同一性を示すことができるため、次のことが言える。
A=B、B=C ならば A=C - 序数尺度
順位、優劣、程度等によって対象の序列を表現した数値。中央値、パーセンタイル、順位相関係数等の統計量が許容される。厳密には値の順序しか意味をもっておらず、数学的には同一性および順位性を示すことができる。ここで、順位性については次のことが言える。
A>B、B>C ならば A>C
A>B、B=C ならば A>C - 間隔尺度
絶対原点はもたないが、尺度上の水準間の距離が等しくなるように数値が割り当てられた尺度。具体的には温度や年号のように間隔尺度同士の乗算・除算は意味をなさない。例えば、気温30度と15度の差は、20度と5度の差に等しいとは言えるが、気温30度は15度の2倍暑いとは言えない。間隔尺度においては、平均、標準偏差、ピアソンの積率相関係数等を算出することができる。また、次の比尺度と同様、量的データとして回帰分析等の多変量解析技法がそのまま適用できる。数学的性質としては、同一性、順位性、加算性が成り立つ。ここで加算性とは、以下のことである。
A=C、B=D ならば A+B=C+D - 比尺度
間隔尺度とは異なり絶対原点をもつなど、上記3つの尺度よりも測定水準のレベルが高いため、数学的には四則演算がすべて可能である。具体例としては、重さ、長さ、時間などである。したがって、対象を識別・分類することができるだけでなく、間隔・差異・平均・比率を論じることも可能である。
【4.質的データ】
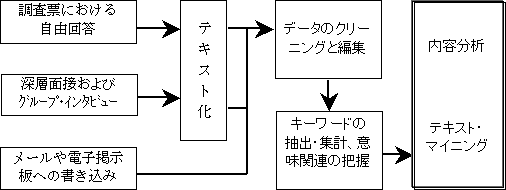
名義尺度や序数尺度によって表現されたデータに加え、インタビューにおけるコメントや調査票における自由回答項目など、そのままでは数量として取り扱うことのできないテキスト・データを総称して質的データという。しかし、テキスト・データでも、その中に含まれるキーワード数を数えることによって、対象の性質を数量的に把握することも可能である。このようにして抽出されたキーワードの意味内容や関連性についても明らかにすることで、対象の深い理解を得ようとするのが内容分析と呼ばれる手法である。また、こうした作業をコンピュータによって自動的かつ迅速に行うための方法がテキスト・マイニングであり、最近ではウェブ調査による自由回答や電子掲示板に書き込まれたコメントなどに次第に適用されつつある。図1はテキスト・データと、その分析方法の関係について示したものである。内容分析やテキスト・マイニングは統計的手法とは異なるが、対象の客観的な記述や理解を得るための分析方法として用いることができる。
なお、質的データは、以下のような有用性をもっている。
- 調査者が予期しないような要因についても情報が入手できる可能性がある。
- 量的データの分析結果に対する理解が質的データの吟味によって深まることがある。
- 対象を記述・理解することで、新たな研究仮説を提供する。
- 特に常識的な仮説に対する反証事例について調べる場合、それが誤差によるものかあるいはその仮説を覆す必要があるのかの判断材料を与えてくれる可能性がある。
他方で、質的データおよびそうしたデータを入手するための定性調査には、以下のような限界や問題点があると考えられる。
- グループ・インタビューや深層面接は、調査者の力量により分析結果が影響されがちである。
- 通常この種の調査においては、サンプル数が少ないため分析結果の一般性は低い。にもかかわらず、探索的分析結果や特異な事例に基づく解釈を、一般的なものとしてしまう恐れがある。
- 回答者の内面に踏み込める可能性は高まるが、反対に、プライバシー等の倫理上の問題が生じ易い。
【5.データにおける時間的性質】
最後に、データの時間的性質について考えてみよう。データは、ある1時点で収集された横断的データと複数の時点で得られた縦断的データとに大別できる。横断的データは、ある変数について同一時点における個々の標本の値を示したデータであり、具体的には、ある時点で多数の標本から得られた質問紙調査における回答や、ある年度の商業統計の集計結果を都道府県別に示したものなどがこれに該当する。このタイプのデータによる変数間の関係は、基本的に相関に基づいており、因果関係を確定するための能力が弱い。しかし、縦断的データに比べ、データの入手が容易であることや予測よりも記述・説明を重視するといった理由から、マーケティング研究の分野では、横断的データを取り扱う分析技法の方が一般によく用いられてきた。
他方、縦断的データには、時間を規則的に追った時系列データや、同じ標本について異なる複数の時点で得られた反復測定データなどがある。特に後者は、同じ対象に対し定期的に行われる調査や複数回にわたる観察等によって得られる。縦断的データは、これまで、計量経済学、医学、教育学等の分野で用いられることが多く、時系列分析(伝達関数モデル等)、コーホート分析、三層データを用いた因子分析など、そのための手法の研究も進んできている。この種のデータは、同一対象の時間的変化を追えるため、その変化の予測や、諸変数間に存在する因果関係の安定性の吟味を可能にする。今後、マーケティング分野でもスキャンパネル・データ等を活用した分析事例が増えてくるものと思われる。
(本稿は「マーケティング研究と統計的手法」『三色旗』第634号(慶應義塾大学通信教育部)14-19頁(2001)を大幅に加筆修正したものです。全文はこちらからダウンロードしてご覧ください。)
- 高橋 郁夫(たかはし・いくお)
-
- 慶應義塾大学商学部教授
- 『マーケティング情報から顧客を読み解く』講師
- 慶應義塾大学商学部卒業。慶應義塾大学大学院商学研究科修士課程・博士課程修了。博士(商学)。国際ロータリー財団奨学生としてノースウェスタン大学大学院に、訪問研究員としてコンコーディア大学(カナダ)、ワシントン大学(アメリカ)に留学。専門は、流通論、マーケティング論、消費者行動論。著書に、『消費者購買行動-小売マーケティングへの写像』(千倉書房)などがある。
登録



登録